
Using statsmodels for Regression¶
In the previous section, we used functions in NumPy and concepts taught in Data 8 to perform single variable regressions. It turns out that there are (several) Python packages that can perform these regressions for us and which extend nicely into the types of regressions we will cover in the next few sections. In this section, we introduce statsmodels for performing single variable regressions, a foundation upon which we will build our discussion of multivariable regression.
statsmodels is a popular Python package used to create and analyze various statistical models. To create a linear regression model in statsmodels, which is generally import as sm, we use the following skeleton code:
x = data.select(features).values # Separate features (independent variables)
y = data.select(target).values # Separate target (outcome variable)
model = sm.OLS(y, sm.add_constant(x)) # Initialize the OLS regression model
result = model.fit() # Fit the regression model and save it to a variable
result.summary() # Display a summary of results
You must manually add a constant column of all 1’s to your independent features. statsmodels will not do this for you and if you fail to do this you will perform a regression without an intercept \(\alpha\) term. This is performed in the third line by calling sm.add_constant on x. Also note that we call .values after we select the columns in x and y; this gives us NumPy arrays containing the corresponding values, since statsmodels can’t process Tables.
Recall the cps dataset we used in the previous section:
cps
| state | age | wagesal | imm | hispanic | black | asian | educ | wage | logwage | female | fedwkr | statewkr | localwkr |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 11 | 44 | 18000 | 0 | 0 | 0 | 0 | 14 | 9.10931 | 2.2093 | 1 | 1 | 0 | 0 |
| 11 | 39 | 18000 | 0 | 0 | 0 | 0 | 14 | 18 | 2.89037 | 0 | 0 | 0 | 0 |
| 11 | 39 | 35600 | 0 | 0 | 0 | 0 | 12 | 17.1154 | 2.83998 | 0 | 0 | 0 | 1 |
| 11 | 39 | 8000 | 0 | 0 | 0 | 0 | 14 | 5.12821 | 1.63476 | 1 | 0 | 0 | 0 |
| 11 | 39 | 100000 | 0 | 0 | 0 | 0 | 16 | 38.4615 | 3.64966 | 0 | 1 | 0 | 0 |
| 11 | 43 | 25000 | 0 | 0 | 0 | 0 | 12 | 10 | 2.30259 | 0 | 0 | 0 | 0 |
| 11 | 38 | 25000 | 0 | 0 | 0 | 0 | 16 | 27.1739 | 3.30226 | 1 | 0 | 0 | 0 |
| 11 | 39 | 26000 | 0 | 0 | 0 | 0 | 13 | 16.6667 | 2.81341 | 1 | 0 | 0 | 0 |
| 11 | 39 | 52000 | 0 | 0 | 0 | 0 | 16 | 16.6667 | 2.81341 | 0 | 0 | 0 | 0 |
| 11 | 37 | 4500 | 0 | 0 | 0 | 0 | 13 | 4 | 1.38629 | 1 | 0 | 0 | 0 |
... (21897 rows omitted)
Let’s use statsmodels to perform our regression of logwage on educ again.
x = cps.select("educ").values
y = cps.select("logwage").values
model = sm.OLS(y, sm.add_constant(x))
results = model.fit()
results.summary()
| Dep. Variable: | y | R-squared: | 0.204 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.204 |
| Method: | Least Squares | F-statistic: | 5600. |
| Date: | Wed, 10 Jun 2020 | Prob (F-statistic): | 0.00 |
| Time: | 10:43:19 | Log-Likelihood: | -20513. |
| No. Observations: | 21907 | AIC: | 4.103e+04 |
| Df Residuals: | 21905 | BIC: | 4.105e+04 |
| Df Model: | 1 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 1.4723 | 0.021 | 71.483 | 0.000 | 1.432 | 1.513 |
| x1 | 0.1078 | 0.001 | 74.831 | 0.000 | 0.105 | 0.111 |
| Omnibus: | 989.972 | Durbin-Watson: | 1.873 |
|---|---|---|---|
| Prob(Omnibus): | 0.000 | Jarque-Bera (JB): | 2802.765 |
| Skew: | 0.201 | Prob(JB): | 0.00 |
| Kurtosis: | 4.706 | Cond. No. | 70.9 |
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
The summary above provides us with a lot of information. Let’s start with the most important pieces: the values of \(\hat{\alpha}\) and \(\hat{\beta}\). The middle table contains these values for us as const and x1’s coef values: we have \(\hat{\alpha}\) is 1.4723 and \(\hat{\beta}\) is 0.1078.
Recall also our discussion of uncertainty in \(\hat{\beta}\). statsmodels provides us with our calculated standard error in the std err column, and we see that the standard error of \(\hat{\beta}\) is 0.001, matching our empirical estimate via bootstrapping from the last section. We can also see the 95% confidence interval that we calculated in the two rightmost columns.
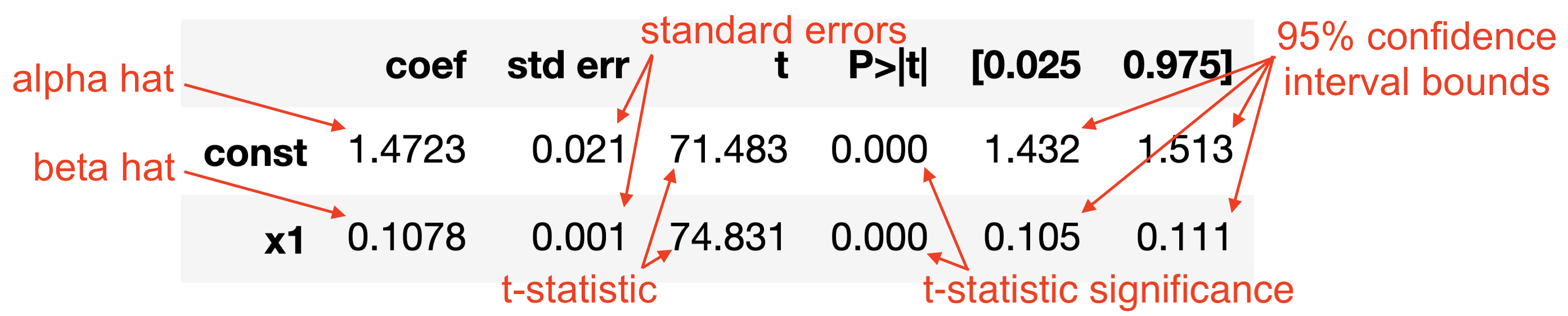
Earlier we said that \(\hat{\beta}\) has some normal distribution with mean \(\beta\) if certain assumptions are satisfied. We now can see that the standard deviation of that normal distribution is the standard error of \(\hat{\beta}\). We can also use this to test a null hypothesis that \(\beta = 0\). To do so, construct a t-statistic (which statsmodels does for you) that indicates how many standard deviations away \(\hat{\beta}\) is from 0, assuming that the distribution of \(\hat{\beta}\) is in fact centered at 0.
We can see that \(\hat{\beta}\) is 74 standard deviations away from the null hypothesis mean of 0, which is an enormous number. How likely do you think it is to draw a random number roughly 74 standard deviations away from the mean, assuming a standard normal distribution? Essentially 0. This is strong evidence that the mean of the distribution (the mean of \(\hat{\beta}\) is the true value \(\beta\)) is not 0. Accompanying the t-statistic is a p-value that indicates the statistical significance.